Chairwood, Sub02, View 0
Chairwood, Sub02, View 2
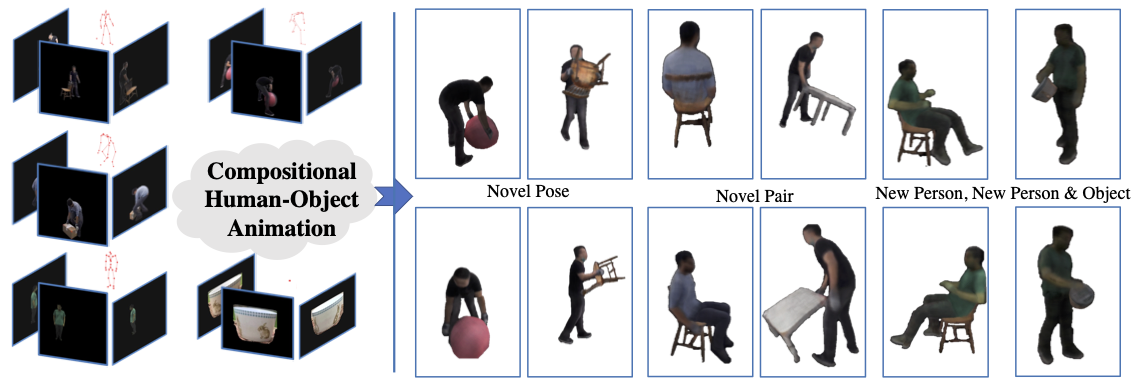
Human-object interactions (HOIs) are crucial for human-centric scene understanding applications such as human-centric visual generation, AR/VR, and robotics. Since existing methods mainly explore capturing HOIs, rendering HOI remains less investigated. In this paper, we address this challenge in HOI animation from a compositional perspective, i.e., animating novel HOIs including novel interaction, novel human and/or novel object driven by a novel pose sequence. Specifically, we adopt neural human-object deformation to model and render HOI dynamics based on implicit neural representations. To enable the interaction pose transferring among different persons and objects, we then devise a new compositional conditional neural radiance field (or CC-NeRF), which decomposes the interdependence between human and object using latent codes to enable compositionally animation control of novel HOIs. Experiments show that the proposed method can generalize well to various novel HOI animation settings.
Chairwood, Sub02, View 0
Chairwood, Sub02, View 2
Yogaball, Sub02, View 0
Yogaball, Sub02, View 2
Chairwood, Sub01, View 0
Chairwood, Sub01, View 2
Yogaball, Sub01, View 0
Yogaball, Sub01, View 2
Chairblack, Sub01, View 0. The first column is the baseline without object modelling.
Chairblack, Sub01, View 2. The first column is the baseline without object modelling.
Tablesquare, Sub01, View 0. The first column is the baseline without object modelling.
Tablesquare, Sub01, View 2. The first column is the baseline without object modelling.
The proposed method with compositional invariant learning is also able to transfer the interaction for novel person and novel objects. The left column indicates the method without compositional invariant learning, the center column shows the proposed method, while right column is the ground truth. We choose two views for demonstration.
@article{hou2023chona,
author = {Hou, Zhi and Yu, Baosheng and Tao, Dacheng},
title = {Compositional 3D Human-Object Neural Animation},
journal = {arXiv preprint arXiv:2304.14070},
year = {2023},
}